"Drop me the score. Say a few words. I'll sing it for you."
AI sight-singing from MusicXML, via chat. No MIDI editing required.
What it does
Turn your MusicXML score into a singing demo in minutes.
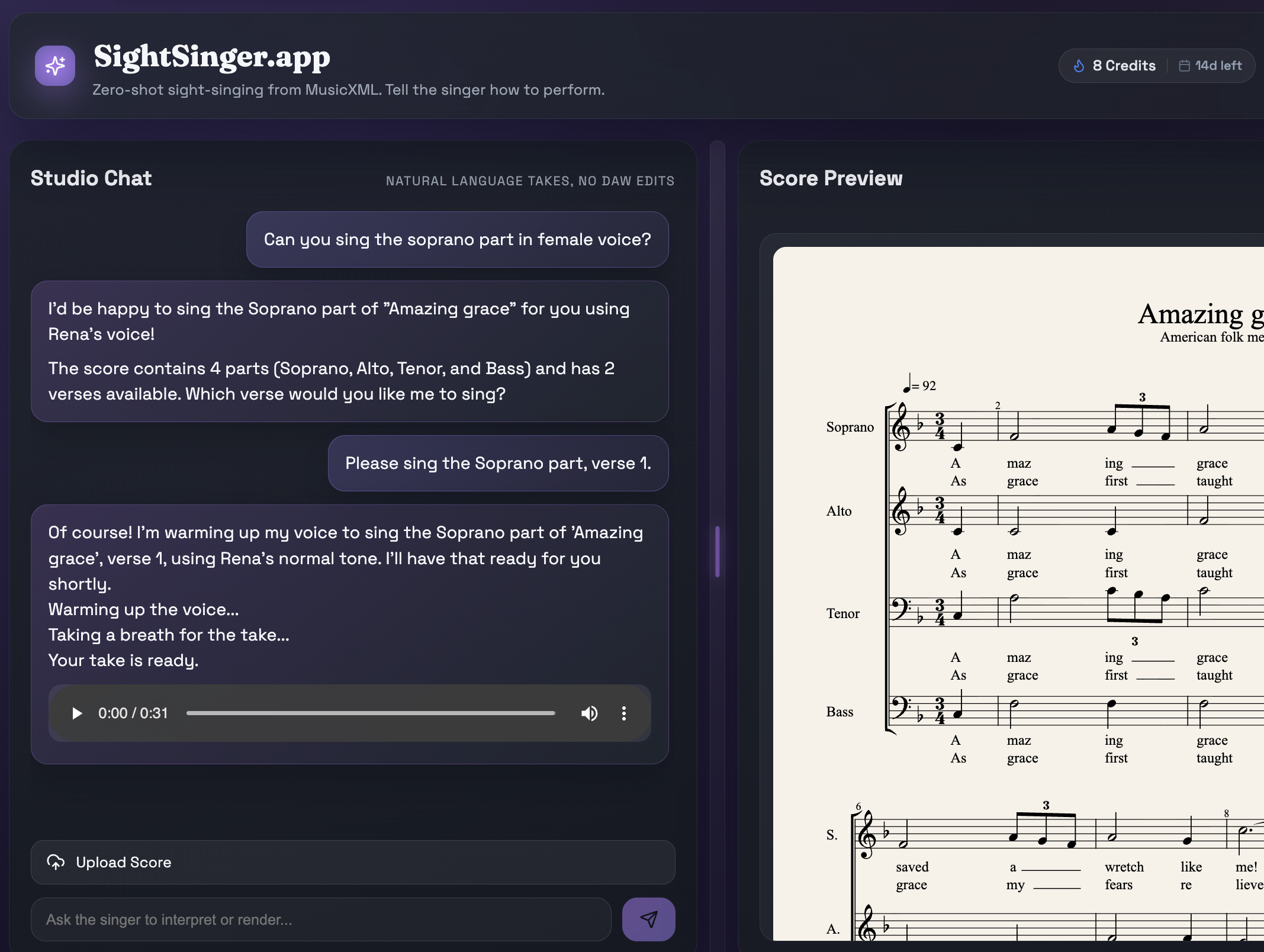
Score - Singing Demo
Upload MusicXML and get a realistic vocal preview without a DAW.
Chat-driven Takes
Ask for parts, verses, and style changes using natural language.
Fast Iteration
Generate multiple interpretations quickly for practice or review.
Who is SightSinger.app for?
Indie Songwriters
"Instant vocal demo"
Get a convincing singing preview fast - no session singer, no studio time.
Choir & Worship Leaders
"Parts in minutes"
Generate SATB (or melody) practice tracks in minutes - save pianist hours of practice and recording time.
Beginner Singers
"Stepping stone"
Try singing with a score-accurate guide before investing in expensive lessons.
Quick Song Learners
"Learn it fast"
Pick up a few songs quickly for occasions without diving into theory or breath training.
SightSinger.app is NOT...
A DAW replacement
It doesn't replace professional vocal synthesis tools. But it can be used to complement them with fast, score-based vocal previews.
A human vocalist
It's a fast, score-accurate singing demo for rehearsal and practice. It doesn't replace human singers or human recordings.
A Song Generator
It doesn't generate songs from text prompts (like Suno). It sings the music you've already written and follows the score exactly.
A Voice Converter
It doesn't convert recorded vocals or require a base audio track. It sings directly from the score.
Why SightSinger.app?
Speak music, not MIDI.
| Feature | SightSinger.app | Professional DAW (Digital Audio Workstation) |
|---|---|---|
| Interface | Natural Language (Chat) | Piano roll, parameters, phonemes |
| Learning Curve | Zero | Steep |
| Focus | Global style control, demo quality | Detailed note-level control, production quality |
| Time to result | Minutes | Hours |
How it works
Upload your score
Drop in MusicXML from MuseScore, Logic Pro, Finale, or Sibelius.
We parse tempo maps, part labels, and lyric syllables with music21.
Tell the singer
Use natural language to pick parts/verses and shape phrasing, tone, and expression.
Gemini Flash 3 calls internal MCP tools to map intent into performance parameters.
Generate the singing voice
SightSinger.app runs a custom singing synthesis pipeline to render a realistic vocal demo directly from the score.
Voicebanks are DiffSinger-compatible OpenUtau ONNX models, so adding new voices is straightforward.
Refine and share
Iterate quickly, render new takes, and export a shareable demo for singers.
AI Voices
Current AI voices are not cleared for commercial use.
Royalty-free voices will be added when paid subscription plans launch.
Raine Reizo
Version 2.0 - by suyu (UtauReizo) - 3 tone colors (normal/soft/strong)
Raine Rena
Version 2.0 - by suyu (UtauReizo) - 3 tone colors (normal/soft/strong)
- Raine Rena
- Fromage
- PJS (relabel by UtaUtaUtau)
- CSD (relabel by heta-tan)
- opencpop (relabel by komisteng)
- m4singer (relabel by nobodyP)
- TGM
Pricing (Will be announced soon)
Credits keep usage predictable. Each credit covers 30 seconds of generated audio.
Credit Based Subscription
Paid plan credits will carry a 1-year expiry so you can cover peak seasons like Christmas.
Pay Only For Output
Credits are reserved pre-render, and consumed when audio is delivered, rounded up to the nearest 30 seconds.
Flexible Usage
Spend credits on one long take or many short parts and verses - it's up to you.
FAQ
About Me
I'm Alan, a software engineer and volunteer musician. I love building things that solve real problems. I'm passionate about using AI to solve my own problem in music, and hopefully it can help you too.